ChatGPT
ChatGPT
 Perplexity
Perplexity
 Claude
Claude


Why Most RAG Chatbots Fail in Production (And What We Built Instead)
📌 TL;DR
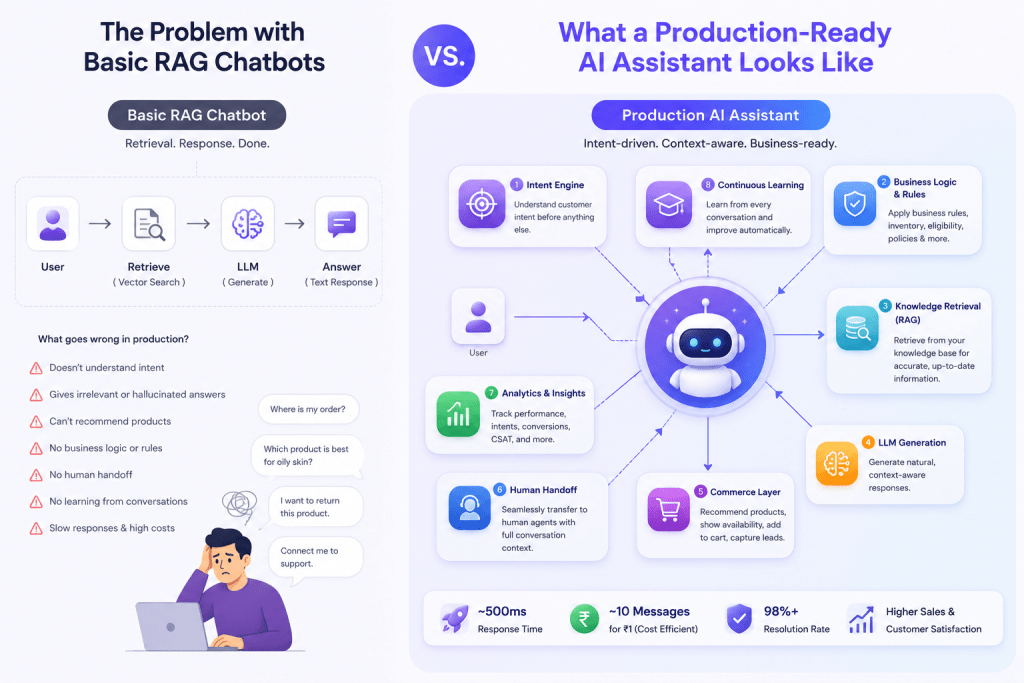
Most ecommerce AI chatbots fail because they rely only on RAG (Retrieval-Augmented Generation). In production, stores need AI that understands customer intent, accesses live business systems, recommends products, handles support workflows, and continuously improves from conversations.
- Simple RAG works for demos—not real ecommerce.
- Customers ask about products, orders, returns, discounts and comparisons.
- Production AI needs an Intent Engine before retrieval.
- Business workflows matter more than document retrieval.
- Fast response time and low cost are essential at scale.
- Continuous learning improves accuracy over time.
Today, almost everyone seems to be building a RAG chatbot today.
A customer lands on a Shopify store and asks:
Another customer asks:
Another asks:
Another asks:
These aren’t knowledge retrieval problems.
They’re business workflow problems.
That’s exactly where most RAG chatbots fail.
With tools like LangChain, vector databases, and modern LLMs, it’s possible to build a working chatbot over a weekend. Ask a question, retrieve a few documents, send them to an LLM, and you’ll get a reasonably good answer.
For a demo, that’s enough.
For a real business, it isn’t.
Once an AI assistant starts talking to hundreds or thousands of customers every day, a completely different set of challenges appears. Customers don’t ask clean questions. They jump between topics, ask vague questions, compare products, check order status, request returns, ask for discounts, and sometimes simply want to speak to a human.
At that point, the problem is no longer “How do we build a RAG chatbot?”
The real question becomes:
How do we build an AI assistant that businesses can actually trust in production?
Over the past few months, we’ve been building exactly that for eCommerce businesses. While RAG is an important part of our architecture, we quickly realized that retrieval alone solves only a small part of the problem. The real engineering challenge lies in everything around it—understanding customer intent, applying business logic, recommending products, integrating support workflows, learning from conversations, and doing all of this at production scale with low latency and sustainable costs.
This article shares what we learned, the architecture we ended up building, and why we believe the next generation of AI assistants will be intent-driven systems, not just retrieval pipelines.
Continue Reading
If you’re building or scaling an ecommerce business, these resources might also help:
The RAG Hype Is Real—But So Are Its Limitations
Retrieval-Augmented Generation (RAG) has become one of the most popular ways to build AI applications. Instead of relying solely on what an LLM already knows, However, retrieval alone wasn’t enough. from your own knowledge base before generating a response. It’s a powerful idea and, when implemented well, significantly improves answer quality.
But after deploying our system into production, we discovered something important:
The retrieval layer was rarely the hardest part of the problem.
The harder questions looked like this:
- What if the customer is asking for a product recommendation instead of factual information?
- What if they want to know where their order is?
- What if they ask three different questions in one message?
- What if they should be transferred to a support agent?
- What if the same question requires different answers depending on business rules or customer context?
A standard RAG pipeline treats every question in roughly the same way.
Real businesses can’t.

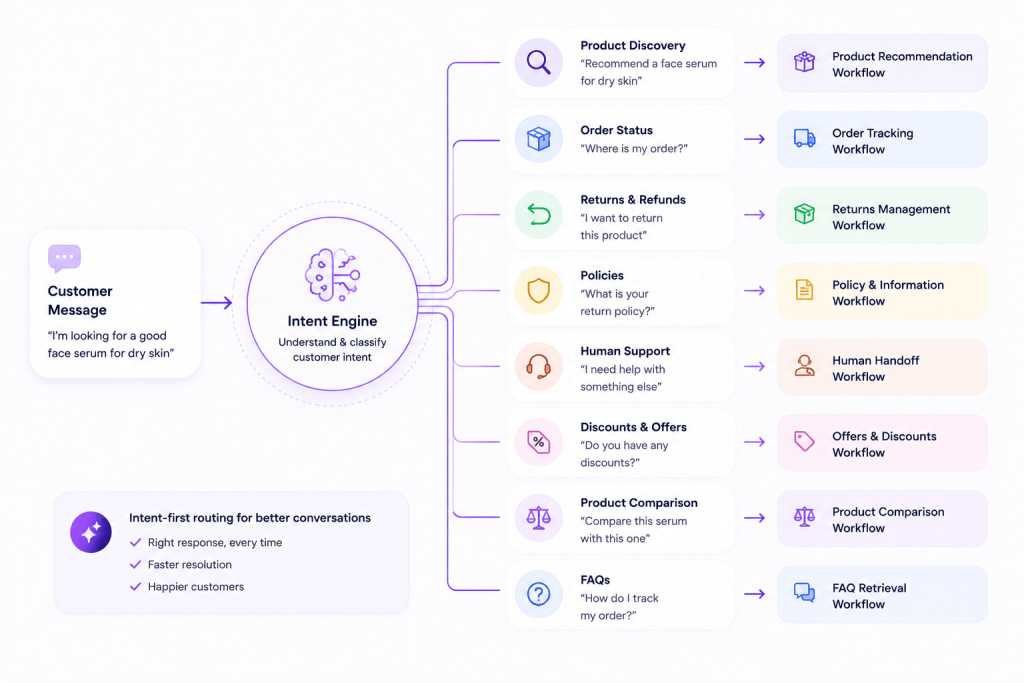
The Biggest Lesson We Learned: Intent Comes Before Retrieval
Building something similar for your yourself? We’re happy to show you the live deployment and answer questions — reach me on WhatsApp or call +91 93547 01759.
One of the biggest architectural decisions we made was placing an Intent Engine before the retrieval layer.
Instead of immediately searching documents for every message, we first try to understand what the customer is actually trying to accomplish.
A customer asking, “Where is my order?” shouldn’t go through the same workflow as someone asking, “Which serum is best for oily skin?”
Likewise, someone asking about a return policy requires a different path than someone comparing two products or requesting a human agent.
By identifying intent first, the system can route each conversation through the most appropriate workflow instead of treating every question as a search problem.
This approach improves answer quality, reduces unnecessary retrieval calls, and creates a much more natural customer experience.
Some of the intents our platform identifies include:
- Product Discovery
- Product Comparison
- Order Status
- Returns & Refunds
- Store Policies
- Human Support
- Discount & Offers
- General FAQs
The result is a system that behaves less like a search engine and more like an experienced sales and support representative.
AI Shouldn’t Just Answer Questions. It Should Help Customers Buy.
Many AI chatbots stop after generating an answer.
We wanted ours to do more.
A customer looking for a product usually doesn’t know the exact SKU or product name. Instead, they describe a problem.
Examples include:
- “I’m looking for a face wash for oily skin.”
- “Suggest running shoes under ₹4,000.”
- “I need a Rudraksha for career growth.”
- “Recommend a lavender body wash.”
These aren’t knowledge retrieval problems.
They’re buying-intent problems.
Our AI assistant combines customer intent, business rules, product data, and retrieval to recommend products conversationally, answer follow-up questions, explain product details, and guide customers toward purchase.
In many cases, the AI becomes the digital equivalent of an in-store sales assistant.
Beyond Support: Building an AI That Understands Business
Support is only one piece of the customer journey.
A production AI assistant should also:
- Answer policy questions
- Explain products
- Recommend alternatives
- Capture leads
- Know when confidence is low
- Escalate conversations to human agents
- Learn from every interaction
This requires multiple systems working together—not just an LLM.
Performance Matters More Than People Think
One lesson became obvious very quickly.
Even the smartest AI feels slow if customers have to wait.
From the beginning, we optimized for production performance instead of demo performance.
Today, our architecture typically responds in around 500 milliseconds, creating conversations that feel fast and natural rather than delayed.
Cost was another important consideration.
Instead of building an architecture that becomes prohibitively expensive as conversations grow, we optimized the pipeline to handle approximately 10 customer messages for around ₹1.
For businesses serving thousands of customers every day, these engineering decisions have a significant impact on scalability and operating costs.
The AI Doesn’t Just Talk. It Learns.
Perhaps the most exciting part of the system isn’t the chatbot itself.
It’s what happens after the conversation ends.
Every customer interaction becomes an opportunity to improve the business.
Instead of manually reading chat transcripts, the platform identifies recurring questions, missing FAQs, customer objections, product knowledge gaps, and buying preferences. These insights help businesses improve their website, documentation, product pages, and customer experience over time.
The AI gradually becomes more useful—not simply because the language model improves, but because the business continuously learns from its customers.

RAG Is the Foundation. Production Engineering Is the Differentiator.
We still believe RAG is one of the most important technologies behind modern AI assistants.
But after deploying our own system, we’ve come to see it differently.
RAG is the foundation—not the finished product.
The real differentiation comes from everything built around it:
- Intent detection
- Business-aware workflows
- Product recommendation logic
- Human handofff
- Analytics
- Continuous learning
- Fast response times
- Cost-efficient architecture
Those are the pieces that transform an impressive demo into a reliable business system.
Comparison Rag Vs Production Ai Assistant
| Basic RAG | Production AI Assistant |
|---|---|
| Retrieves documents | Understands customer intent |
| Answers FAQs | Handles business workflows |
| Static knowledge | Uses live business systems |
| Generic responses | Personalized recommendations |
| No analytics | Learns from conversations |
| No escalation | Human handoff |
Key Takeaways
- A basic RAG pipeline is not enough for production ecommerce.
- Intent detection should happen before retrieval.
- Product discovery and customer support require different workflows.
- AI should connect with business logic, not just documents.
- Human handoff is essential for complex conversations.
- Analytics help improve both the AI and the business.
- Low latency and low inference cost matter as much as answer quality.
What’s Next
In this article, we focused on the architectural lessons we learned while building a production-ready AI assistant.
In the next articles, we’ll go deeper into the engineering itself, including:
- How our Intent Engine works
- How we optimized response time to around 500 ms
- How we reduced inference costs without sacrificing quality
- The architecture behind our retrieval pipeline
- Lessons learned after thousands of real customer conversations
If you’re building AI products for real businesses—not just demos—we hope these insights help you avoid some of the challenges we encountered along the way.
Frequently Asked Questions
What is a RAG chatbot?
Why do most RAG chatbots fail in production?
How is a production AI assistant different from a basic RAG chatbot?
Can AI chatbots recommend products on Shopify?
Does an AI shopping assistant reduce customer support tickets?
Can AI chatbots integrate with Shopify?
See What Production AI Looks Like
This article explained why most RAG chatbots struggle in production. If you’re running a Shopify store and want to see what a production-ready AI shopping assistant looks like, we’ve built one that focuses on real business outcomes—not just answering questions.
- ✅ AI Product Recommendations
- ✅ Order Tracking
- ✅ Customer Support
- ✅ Human Handoff
- ✅ Shopify Integration
- ✅ Analytics & Continuous Learning